**해당 데이터는 제가 학원 강의를 수료하며 받은 데이터이며 원본 데이터는 기업으로부터 제공받은 데이터라서 공유할 수 없습니다.
**본문은 공부를 하며 과정을 이해하며 생각하기 위함이니 참고 해주시면 감사드리겠습니다.
## Environment : Anaconda-navigator
## Programming Language : Python 3
## Import Pandas
## Data provided by DS school & Origin data from Kmong.
## Kmong is a company that has a dream as below.
Kmong은 "비합리적인 서비스 시장을 정보기술로 혁신하여 새로운 일자리를 만들고 사람들이 행복하게 일하는 세상을 만든다."는 미션을 가지고 있는 프리랜서 마켓 플랫폼입니다.
Kmong팀은 디자인, 마케팅, IT&개발, 컨텐츠 제작, 통번역 등 다양한 서비스 카테고리를 기반으로 직업과 직장의 경계를 허물며 사람들이 스스로 경제 주체가 되어 행복하게 일하는 세상을 만들고 있습니다.
Target
- 데이터를 불러오기 및 전반적인 정보 확인
- 불러온 데이터들을 전처리
- 데이터들 목적에 맞게 병합
분석 시작
1. 데이터 불러오기 및 전반적인 정보 확인
Python의 import를 활용해 데이터 분석용 패키지인 판다스(Pandas)를 읽어옵니다.
import pandas as pd판다스 데이터프레임(DataFrame)을 출력할 때, 여러컬럼을 편하게 보기 위해 최대 출력 컬럼을 30개로 늘려줍니다.
pd.options.display.max_columns = 30데이터 로딩하기 - 데이터를 읽어올때는 판다스(Pandas)의 read_csv 라는 기능을 사용합니다.
read_csv를 실행할 때 (FileNotFoundError)라는 이름의 에러가 난다면 경로가 제대로 지정이 되지 않은 것입니다.
경로를 지정하는 법은 아래 링크를 참고해주세요.(판다스 공식 참고 페이지입니다.)
http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html
판다스(pandas)의 read_csv를 활용하여 크몽의 전환 정보(conversion) 관련 기록을 저장한 아래 csv 파일을 읽어옵니다.
이 데이터를 raw_log_data라는 이름의 변수에 할당합니다.
raw_log_data = pd.read_csv("kmong-conversion.csv")
raw_log_data 변수에 할당된 데이터의 행렬 사이즈를 출력합니다. 결과는 row & column 으로 표시됩니다.
raw_log_data의 컬럼 리스트를 출력합니다.
print(raw_log_data.shape)
print(raw_log_data.column())
다음은 간편하게 데이터를 훑기 위해 head()로 raw_log_data 데이터의 상위 5개를 띄웁니다.
- head는 괄호() 안에 숫자를 넣어 원하는 만큼 raw를 출력할 수 있습니다. 기본은 5개입니다.
raw_log_data.head()
2. 불러온 데이터들을 전처리
다음으로 Data 과학자들이 일을 하면서 가장 많은 시간을 소모하는 전처리 과정으로 들어가겠습니다.(참고 내용 From Forbes)

raw_log_data를 보시면 컬럼 중 'canonicaldeviceuuid'라는 컬럼이 있습니다. 이 부분을 직관적으로 이해하기 편하도록 'userid'라는 컬럼으로 변경(기존 데이터로 새로운 컬럼 생성)하도록 하겠습니다.
raw_log_data['user_id'] = raw_log_data['canonicaldeviceuuid']
print(raw_log_data.shape)을 통해 관련 총 데이터 개수와 열 확인을 할 수 있습니다
보기 편하도록 raw_log_data에서 아래 2개 컬럼만 내용 결과 확인합니다.
print(raw_log_data.shape)
raw_log_data[['canonicaldeviceuuid', 'userid']].head()
'eventdatetime' 컬럼은 보기에는 날짜 시간 형식으로 보이지만 아래처럼 현재 dtype이 object로 되어있습니다.
raw_log_data['eventdatetime']
'eventdatetime' 컬럼에 있는 값을 판다스의 to_datetime이라는 함수를 사용해서 날짜와 시간을 표현할 수 있는 datetime 형태로 변경합니다. - 첫째줄 아래 오른쪽 code에서 to_datetime 함수를 사용하여 'eventdatetime'이라는 컬럼에 기능을 부여하고 그 부여된 기능이 왼쪽편 'eventdatetime'에 적용되었다고 생각하시면 됩니다.
raw_log_data["eventdatetime"] = pd.to_datetime(raw_log_data["eventdatetime"])
적용 후 값을 출력해봅니다.
print(raw_log_data.dtypes) # raw_log_data의 dtype들 모두 보여줌
raw_log_data["eventdatetime"]
아래 보시는바와 같이 'eventdatetime'컬럼이 datetime64 형태로 잘 적용된걸 확인 하실 수 있습니다.

새로운 컬럼을 생성하며 연, 월, 일, 시, 분 그리고 초 단위로 나누는 작업은 1-6 line처럼 dt.xx(dt = datetime의 약자입니다)를 활용하여 분류하실 수 있습니다.
마지막줄은 새로 생성한 6개 컬럼의 결과를 보여줍니다.
raw_log_data["eventdatetime_year"] = raw_log_data["eventdatetime"].dt.year
raw_log_data["eventdatetime_month"] = raw_log_data["eventdatetime"].dt.month
raw_log_data["eventdatetime_day"] = raw_log_data["eventdatetime"].dt.day
raw_log_data["eventdatetime_hour"] = raw_log_data["eventdatetime"].dt.hour
raw_log_data["eventdatetime_minute"] = raw_log_data["eventdatetime"].dt.minute
raw_log_data["eventdatetime_second"] = raw_log_data["eventdatetime"].dt.second
print(raw_log_data.shape) # 내용 변경 후 row와 컬럼 형태 확인
raw_log_data[["eventdatetime", "eventdatetime_year", "eventdatetime_month",\
"eventdatetime_day", "eventdatetime_hour", "eventdatetime_minute",\
"eventdatetime_second"]].head()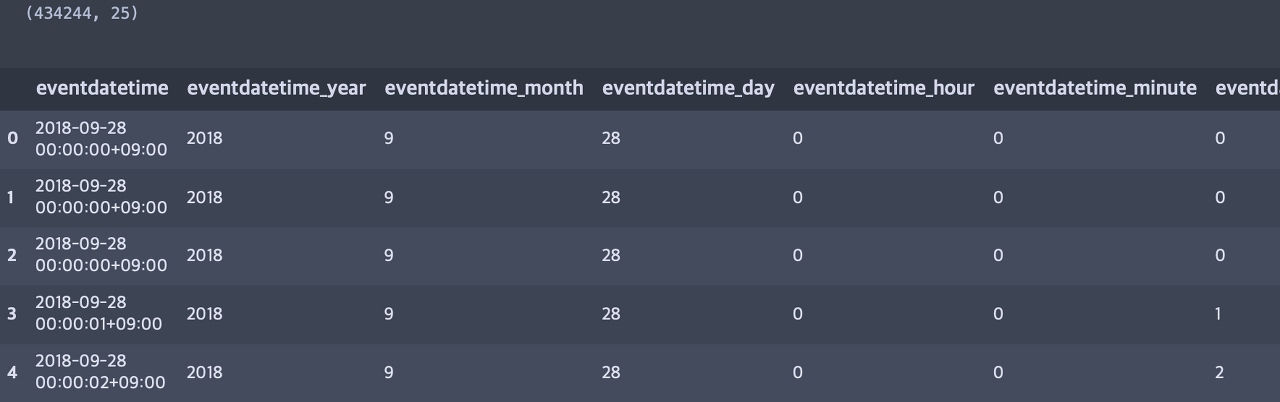
다음 페이지에서는 본 환경을 이어서 동일한 데이터를 가지고 추가적인 전처리를 진행하도록 하겠습니다.
*** 본 페이지는 본인의 공부를 위해 작성되었으며, 협찬이나 문의를 받고 기재한 내용이 아닙니다. 혹시 문의사항이 있으시거나 문제가 될 경우 연락 주시기 바랍니다.***
'데이터 분석 > Python - 정리하자' 카테고리의 다른 글
| 퍼널(Funnel) 데이터를 정리 해보자 (2) | 2024.07.05 |
|---|---|
| 불필요한 컬럼 정리 해보자 (0) | 2024.07.05 |
| 컬럼값 정리 후 결과 확인 해보기 (0) | 2024.07.05 |
| 전처리 중 컬럼 정리 및 시각화 해보기 (2) | 2024.07.05 |
| 데이터 전처리 연속하기 (0) | 2024.07.05 |



