**해당 데이터는 제가 학원 강의를 수료하며 받은 데이터이며 원본 데이터는 기업으로부터 제공받은 데이터라서 공유할 수 없습니다.
**본문은 공부를 하며 과정을 이해하며 생각하기 위함이니 참고 해주시면 감사드리겠습니다.
## Environment : Anaconda-navigator
## Programming Language : Python 3
## Import Pandas
## import seaborn as sns
## import matplotlib as mpl
## import matplotlib pyplot as plt
## Data provided by DS school & Origin data from Kmong.
## Kmong is a company that has a dream as below.
Kmong은 "비합리적인 서비스 시장을 정보기술로 혁신하여 새로운 일자리를 만들고 사람들이 행복하게 일하는 세상을 만든다."는 미션을 가지고 있는 프리랜서 마켓 플랫폼입니다.
Kmong팀은 디자인, 마케팅, IT&개발, 컨텐츠 제작, 통번역 등 다양한 서비스 카테고리를 기반으로 직업과 직장의 경계를 허물며 사람들이 스스로 경제 주체가 되어 행복하게 일하는 세상을 만들고 있습니다.
Target
- 데이터를 불러오기 및 전반적인 정보 확인
- 불러온 데이터들을 전처리
- 데이터들 목적에 맞게 병합
저번 글에 이어 데이터들 전처리를 진행하도록 하겠습니다.
이번에는 channel 이라는 컬럼을 정리해보도록 하겠습니다.
해당 컬럼은 사용자가 크몽 서비스에 유입된 경로를 기록한 정보입니다.
raw_log_data['channel'].value_counts()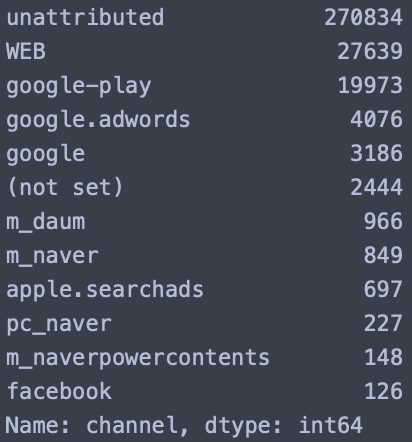
위 결과를 보시면 다양한 채널을 통해 유입된걸 확인하실 수 있으며, 편한 분석을 위해 아래와 같은 조건으로 정리해보도록 하겠습니다.
- 컬럼값에 google이라고 들어간 값(예: google-play, google.adwords, etc)은 전부 google로 통일합니다.
- 컬럼값에 daum이라고 들어간 값(예: m_daum, etc)은 전부 daum으로 통일합니다.
- 컬럼값이 naver라고 들어간 값(예: m_naver, pc_naver, m_naverpowercontents, etc)은 전부 naver로 통일합니다.
- 컬럼값에 apple이라고 들어간 값(예: apple.searchads, etc)은 전부 apple로 통일합니다.
- 컬럼값에 WEB이라고 들어간 값(예: WEB)은 전부 web으로 통일합니다.
첫번째로 Nan값이 있는지 확인합니다.
raw_log_data['channel'].isnull().value_counts() # isnull은 해당 값에 Nan값의 유무를 알려줍니다.
True 값은 Nan값의 개수를 나타내며 해당 컬럼에서는 Nan값을 모두 nan값으로 정리하도록 하겠습니다.
import numpy as np # numpy를 호출합니다.
def channel_clean(channel):
if pd.isnull(channel): # isnull값일 경우
return np.nan # np.nan을 반환합니다
elif "google" in channel: # 내용 안에 google 이라는 string이 있다면
return "google" # google을 반환합니다
elif "daum" in channel: # 내용 안에 daum 이라는 string이 있다면
return "daum" # daum을 반환합니다
elif "naver" in channel: # 내용 안에 naver 라는 string이 있다면
return "naver" # naver를 반환합니다
elif "apple" in channel: # 내용 안에 apple 이라는 string이 있다면
return "apple" # apple을 반환합니다
elif "WEB" in channel: # 내용 안에 WEB 이라는 string이 있다면
return "web" # web을 반환합니다
else: # 그 외에는
return channel # channel 안에 있는값 그대로를 반환합니다.** numpy package에 대해 궁금하시다면 우측 링크를 참조해주세요. https://wikidocs.net/32829
위 definition을 새로운 channel(clean)이라는 컬럼에 적용 후 내용을 확인해 봅시다.
raw_log_data['channel(clean)'] = raw_log_data['channel'].apply(channel_clean)
raw_log_data['channel(clean)'].value_counts()
channel_clean이 잘 적용 되었습니다.
이번에는 inappeventcategory 라는 컬럼을 정리해보겠습니다.
raw_log_data['inappeventcategory'].head(10).dropna()
# 정렬 조건 예를 더 보여드리기 위해 Nan 값은 빼고 출력했습니다. 실제 컬럼에서는 Nan 값도 함께 정렬합니다.
inappeventcategory에는 사용자 액티비티를 나타내는 정보가 들어있습니다.
해당 앱에 방문한 고객이 상품 페이지를 보고 있는지, 구매를 진행중인지 등에 대한 정보가 이 컬럼에 담겨있다고 보시면 됩니다
또한 inappeventcategory에 있는 정보는 차후 퍼널(funnel) 데이터를 합치는데 사용되기도 합니다.
이 데이터를 아래와 같이 정리 해보겠습니다.
- view_category - inappeventcategory에서 언더바(_)를 기준으로 왼쪽 텍스트만 가져옵니다. 언더바가 없을 경우 점(.)의 왼쪽 텍스트만 가져옵니다.
- view_id - inappeventcategory에서 점(.)의 왼쪽 텍스트만 가져옵니다.
- view_action - inappeventcategory에서 점(.)의 오른쪽 텍스트만 가져옵니다.
결론값은 아래와같이 나오도록 합니다.

결론 도출을 위해 하나씩 진행해보도록 하겠습니다.
view_category 컬럼을 위한 definition을 coding 해봅니다.
# view_category 컬럼을 위한 함수입니다.
def clean_category(inappeventcategory):
if pd.isnull(inappeventcategory): # nan 값이 있다면
return np.nan # np.nan 출력합니다
split_dot_left = inappeventcategory.split(".")[0] # "." 기준으로 왼쪽편 반환
view_category = split_dot_left.split("_")[0] # split_dot 값에서 "_" 기준으로 왼쪽편 반환
return view_category # view_category를 출력합니다clean_category가 잘 작동하는지 확인해봅니다.
print(clean_category("home.view")) # "내용"이 clean_category안에서 어떻게 작동하는지 확인
print(clean_category("buyer_order_track.view")) # "내용"이 clean_category안에서 어떻게 작동하는지 확인view_category 컬럼은 "_" 왼쪽 텍스트, "_"가 없다면 "."의 왼쪽 텍스트를 가져옵니다.

결과가 잘 출력 되었습니다.
다음 view_id 컬럼을 위한 definition을 coding 해봅니다.
# view_id 컬럼을 위한 함수입니다.
def clean_id(inappeventcategory):
if pd.isnull(inappeventcategory): # nan 값이 있다면
return np.nan # np.nan 출력합니다
split_dot_left = inappeventcategory.split(".")[0] # "." 기준으로 왼쪽편 반환
return split_dot_left # split_dot_left를 출력합니다clean_id 가 잘 작동하는지 확인해봅니다.
print(clean_id("gig_detail.view")) # "내용"이 clean_id안에서 어떻게 작동하는지 확인
print(clean_id("buyer_order_track.view")) # "내용"이 clean_id안에서 어떻게 작동하는지 확인view_id 컬럼은 "." 왼쪽 텍스트를 가져옵니다.
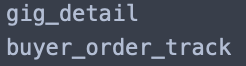
결과가 잘 출력 되었습니다.
다음 view_action 컬럼을 위한 definition을 coding 해봅니다.
# view_action 컬럼을 위한 함수입니다.
def clean_action(inappeventcategory):
if pd.isnull(inappeventcategory): # nan 값이 있다면
return np.nan # np.nan 출력합니다
split_dot_right = inappeventcategory.split(".")[1] # "." 기준으로 오른쪽편 반환
return split_dot_right # split_dot_right을 출력합니다clean_action 이 잘 작동하는지 확인해봅니다.
print(clean_action("gig_detail.view")) # "내용"이 clean_action안에서 어떻게 작동하는지 확인
print(clean_action("buyer_order_track.view")) # "내용"이 clean_action안에서 어떻게 작동하는지 확인view_action 컬럼은 "." 오른쪽 텍스트를 가져옵니다.

결과가 잘 출력 되었습니다.
이제 위에 coding 해놓은 definition들을 적용해 view_category, view_id 그리고 view_action 컬럼을 만들어 봅니다.
raw_log_data['view_catogory'] = raw_log_data['inappeventcategory'].apply(clean_category)
raw_log_data['view_id'] = raw_log_data['inappeventcategory'].apply(clean_id)
raw_log_data['view_action'] = raw_log_data['inappeventcategory'].apply(clean_action)
raw_log_data[['inappeventcategory','view_catogory','view_id','view_action']].head()
내용이 잘 적용되었습니다.
다음 페이지에서는 본 환경을 이어서 동일한 데이터를 가지고 추가적인 전처리를 진행하도록 하겠습니다.
*** 본 페이지는 본인의 공부를 위해 작성되었으며, 협찬이나 문의를 받고 기재한 내용이 아닙니다. 혹시 문의사항이 있으시거나 문제가 될 경우 연락 주시기 바랍니다.***
'데이터 분석 > Python - 정리하자' 카테고리의 다른 글
| 퍼널(Funnel) 데이터를 정리 해보자 (2) | 2024.07.05 |
|---|---|
| 불필요한 컬럼 정리 해보자 (0) | 2024.07.05 |
| 전처리 중 컬럼 정리 및 시각화 해보기 (2) | 2024.07.05 |
| 데이터 전처리 연속하기 (0) | 2024.07.05 |
| 데이터를 불러오기부터 전처리 해보기 (0) | 2024.07.04 |



