**해당 데이터는 제가 학원 강의를 수료하며 받은 데이터이며 원본 데이터는 기업으로부터 제공받은 데이터라서 공유할 수 없습니다.
**본문은 공부를 하며 과정을 이해하며 생각하기 위함이니 참고 해주시면 감사드리겠습니다.
## Environment : Anaconda-navigator
## Programming Language : Python 3
## Import Pandas as pd
## import Numpy as np
## import seaborn as sns
## import matplotlib as mpl
## import matplotlib pyplot as plt
## Data provided by DS school & Origin data from Noom.
## Noom is a company that mentioned as below.
눔(Noom Inc.)은 모바일 플랫폼을 통해 건강관리 서비스를 제공하는 회사로서 2008년, 정세주 대표와 구글 수석 엔지니어 출신이자 공동창업자인 아텀 페타코브(Artem Petakov)에 의해 설립되었습니다. 눔(Noom)은 미국, 일본, 독일, 한국 등 14개국에서 4,600만명이 가입한 글로벌 서비스로 성장하였고, 2009년과 2010년 연이어 구글(Google) 이 선정한 가장 혁신적인 개발 스타트업 중 하나로 선정되었습니다.
Target
- 데이터를 불러오기 및 전반적인 정보 확인
- 불러온 데이터들을 전처리
- 데이터 분석
이번에는 마케팅 채널별 결제/캔슬/환불 비율을 알아 보겠습니다. 현재 눔에서 눔코치를 위해 운영중인 마케팅 채널은 크게 다음과 같습니다.
clean_data["Channel"].value_counts()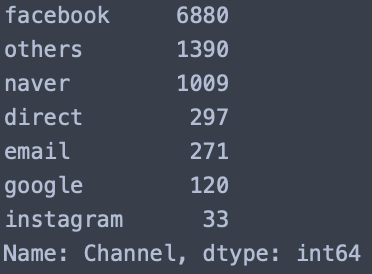
이 채널별 마케팅 효율 정보를 알 수 있다면, 마케팅 팀에서 마케팅 예산을 재조정하여 1) 마케팅 효율이 좋은 채널에 예산을 집중하고, 2) 반대로 마케팅 효율이 좋지 않은 채널에 예산을 빼는 재조정(rebalancing)을 할 수 있습니다.
그러므로 채널별 마케팅 결제/캔슬/환불 현황을 구해보겠습니다.
# pivot_table을 사용하여 index(세로)에는 Channel를 넣어주고, Columns(가로)에는 Status를 넣어줍니다
# 여기서 fill_value에 0을 넣어줘야, 데이터가 없을 경우 NaN이 아닌 0이 나옵니다
# 그리고 aggfunc에 len 를 넣어주면 cancelled, completed, refunded의 누적 개수가 나옵니다
table_by_channel = pd.pivot_table(clean_data,
index='Channel',
columns="Status",
values="Gender",
fill_value=0,
aggfunc=len)
# completed, cancelled, refunded의 총 인원 수를 더해서 total이라는 새로운 컬럼을 추가합니다
table_by_channel["total"] = table_by_channel["completed"] + table_by_channel["cancelled"] + table_by_channel["refunded"]
# 위에서 추가한 total이라는 컬럼으로 completed(결제 완료) 컬럼을 나누면 결제 확률, 전환율(Conversion)이 나옵니다
table_by_channel["conversion"] = table_by_channel["completed"] / table_by_channel["total"]
# 결과를 확인합니다
table_by_channel
이 결과를 통해 알 수 있는 정보는 다음과 같습니다.
- 현재 가장 많은 구매가 일어나는 채널은 페이스북(facebook) 입니다. 거의 대부분의 구매가 이 채널에서 일어났습니다.
- 구매량이 100회 이상인 채널 중 가장 전환율이 높은 채널은 이메일(email) 입니다. 이 채널은 사용자가 눔의 웹사이트에 방문한 뒤, 바로 구매하지 않고 이메일 주소만만 남겨놨을 경우에 해당됩니다.
- 아직 구매량이 페이스북만큼 많지는 않지만, 전환률이 페이스북보다 높은 채널 중 하나는 네이버(naver)입니다. 전환율이 56%로 페이스북보다 다소 높은 편입니다.
- 네이버만큼이나 전환율이 높은 채널은 기타(others)입니다. 이 채널은 결제율이 페이스북만큼 높음에도 불구하고, 아쉽게도 기록이 잘 되어있지 않기 때문에 분석이 어렵습니다.
이 분석 결과를 통해 얻을 수 있는 아이디어는 다음과 같습니다.
- 먼저 내부에서 트래킹 코드나 데이터 클리닝 코드를 수정하여, 기타(others) 채널을 더 세분화시킬 필요가 있습니다. 기타 채널은 1) 페이스북 만큼이나 구매량이 많으며, 2) 전환율이 페이스북보다 높습니다. 이 채널을 더 세분화시켜 분석한다면 마케팅 효율을 높일 수 있는 새로운 아이디어가 나올 수 있습니다.
- 페이스북 다음으로 네이버 검색채널을 집중적으로 튜닝하거나 예산을 배정하여 마케팅 채널을 다각화할 수 있습니다.
- 이메일(email)로 들어온 사용자가 전환율이 높은 이유를 더 분석할 수 있다면 좋겠습니다. 추측컨데, 눔 코치에 대한 신뢰도를 높일 다양한 정보를 이메일로 수신하였기 때문에 다른 채널에 비해 전환율이 높다는 가설을 세울 수 있습니다. 이 가설이 맞다면, 눔 코치를 이용하는 다른 사용자에게도 동일한 정보를 제공한다면 전체 전환율을 높일 수 있을 것입니다.
코치 데이터와 매칭
다음은 사용자 데이터와 코치 데이터를 합쳐서 분석해보겠습니다. 코치 데이터 분석에서 가장 중요한 것은, 좋은 코칭을 하는 사람과 그렇지 못한 사람을 구분하는 것입니다.
코칭팀에서는 좋은 코칭을 하는 코치의 노하우를 정리하여 다른 코치들에게 전파할 필요가 있고, 정 반대로 좋지 않은 코칭을 하는 코치와는 개별 면담을 통해 코칭 퀄리티를 높여야 합니다. 좋은 코칭과 좋지 않은 코칭은 결제 비율과 캔슬 비율, 그리고 환불 비율로 판단할 수 있습니다.
이번에는 데이터 분석을 통해 눔 코치 서비스의 코칭 만족도를 분석해보겠습니다.
# 먼저 코칭 데이터를 가져옵니다
# 이 결과를 coach라는 이름의 변수에 할당합니다
coach = pd.read_csv("noom_coach.csv", index_col="Access Code")
# coach 변수에 할당된 데이터의 행렬 사이즈(row, column)를 출력합니다
print(coach.shape)
# coach 데이터의 상위 5개를 출력합니다
coach.head()
여기서 인덱스(index)는 눔 코치 사용자들의 아이디(Access Code), 열(column)은 코치들의 이름과 아이디(Access Code)입니다. 값은 코치가 사용자에게 코칭을 한 횟수를 나타냅니다. (한 명의 사용자가 여러 명의 코치에게 코칭을 받는 것도 가능합니다)
기존 데이터와 코치 데이터를 합친 후 분석을 진행 해보겠습니다.
# 병합 후 데이터 분석에 필요한 컬럼들만 선택 후 for_merge란 변수에 저장합니다
for_merge = clean_data[['Name', 'Status']]
# 상위 5개 행을 확인합니다
for_merge.head()
# 위에서 저장한 for_merge와 coach 데이터를 concat 후 coach_clean이라는 변수에 저장합니다
coach_clean = pd.concat([for_merge, coach], axis=1)
# coach_clean 변수에 할당된 데이터의 행렬 사이즈(row, column)를 출력합니다
print(coach_clean.shape)
# coach_clean 데이터의 상위 5개를 출력합니다
coach_clean.head()
코치별 담당 사용자(total) / 구매 완료 횟수(completed) / 캔슬 횟수(canceled) / 환불 횟수(refunded)를 구해보겠습니다.
이 수치를 통해 좋은 코칭을 하는 사람과 좋은 코칭을 하지 못하는 사람을 구분할 수 있습니다.
# Status의 종류에 따라 코치들의 실적을 확인합니다.
# .T는 행렬을 반전 시킵니다
# coach_status에 coding한 내용들을 저장합니다
coach_status = coach_clean.pivot_table(index='Status', aggfunc='sum').T
# coach_status의 상위 5개 행을 보여줍니다
coach_status.head()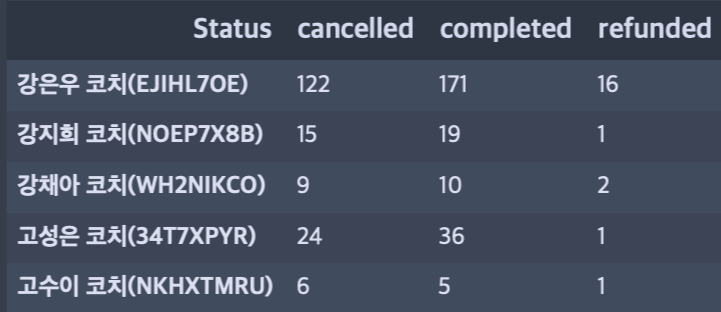
코치별 전환율(conversion rate) / 취소율(cancellation rate)를 계산해 보겠습니다.
여기서 전환율은 전체 구매자 대비 구매 완료(completed)를 한 사람, 취소율은 전체 구매자 대비 취소(cancelled)나 환불(refunded)을 한 사람을 나타냅니다. 이 두 개를 구한 뒤, 1) 전환율이 높은 코치, 2) 취소율이 높은 코치 순으로 정렬해주세요. 단 모수가 부족한 경우를 배제하기 위해, 코칭을 100회 이상 하지 않은 사용자는 배제하도록 하겠습니다.
# cancelled, completed, refunded의 총 인원 수를 더해서 total이라는 새로운 컬럼을 추가합니다
coach_status['total'] = coach_status['cancelled'] + coach_status['completed'] + coach_status['refunded']
# 위에서 추가한 total이라는 컬럼으로 completed(결제 완료) 컬럼을 나누면 결제 확률, 전환율(Conversion)이 나옵니다
coach_status['conversion rate'] = coach_status['completed'] / coach_status['total']
# 위에서 추가한 total이라는 컬럼으로 cancelled(결제 취소) 컬럼을 나누면 취소 확률, 취소율(cancellation)이 나옵니다
coach_status['cancellation rate'] = coach_status['cancelled'] / coach_status['total']
# coach_status 데이터의 상위 5개를 출력합니다
coach_status.head()컬럼들을 생성해 보겠습니다.

이제 코칭 100회 미만 사용자는 배제 후 1), 2) 번 사항을 순차적으로 확인해보겠습니다.
# 모수가 적은 경우를 배제하기 위해, 최소 100명의 고객을 코칭한 코치만을 대상으로 계산합니다
coach_experts = coach_status[coach_status["total"] >= 100]
# coach_experts 변수에 할당된 데이터의 행렬 사이즈(row, column)를 출력합니다
print(coach_experts.shape)
# coach_experts 데이터의 상위 5개를 출력합니다
coach_experts.head()
전환율이 높을수록 해당 코치가 고객에게 만족스러운 코칭을 제공한다고 볼 수 있으며, 해당 코치의 노하우를 다른 코치들에게 전파할 수 있도록 노력해야 합니다. 전환율이 높은 코치들 순서로 확인해보겠습니다.
coach_experts.sort_values('conversion rate', ascending=False).head()
반면 취소율이 높을수록 해당 코치가 고객에게 만족스럽지 않은 코칭을 제공한다고 볼 수 있습니다. 이럴 경우 구체적으로 어떤 부분에서 문제가 생겼는지를 코칭팀에서 파악하여 이를 수정할 수 있어야 합니다. 취소율이 높은 코치들 순서로 확인해보겠습니다.
coach_experts.sort_values('cancellation rate', ascending=False).head()
이제 이 결과를 바탕으로, 고객에게 만족도를 높일 수 있도록 코칭을 개선할 수 있을 것입니다.
다음은 직무교육 스타트업으로 데이터 사이언스와 데이터 마케팅 수업을 진행하고 있는 DS 스쿨의 데이터를 가지고 분석을 진행해보도록 하겠습니다.
*** 본 페이지는 본인의 공부를 위해 작성되었으며, 협찬이나 문의를 받고 기재한 내용이 아닙니다. 혹시 문의사항이 있으시거나 문제가 될 경우 연락 주시기 바랍니다.***
'데이터 분석 > Python - 정리하자' 카테고리의 다른 글
| Python - 양식 통일하기 (0) | 2024.07.09 |
|---|---|
| 직무교육 스타트업 데이터로 전처리 (1) | 2024.07.09 |
| 전환율(conversion) 구해보기 (+시각화) (0) | 2024.07.08 |
| 결제 / 캔슬 / 환불의 총 인원 수와 비율 구해보기 (2) | 2024.07.07 |
| VIP 찾기 데이터 분석 (0) | 2024.07.07 |



