**해당 데이터는 제가 학원 강의를 수료하며 받은 데이터이며 원본 데이터는 기업으로부터 제공받은 데이터라서 공유할 수 없습니다.
**본문은 공부를 하며 과정을 이해하며 생각하기 위함이니 참고 해주시면 감사드리겠습니다.
## Environment : Anaconda-navigator
## Programming Language : Python 3
## Import Pandas as pd
## import Numpy as np
## import seaborn as sns
## import matplotlib as mpl
## import matplotlib pyplot as plt
## Data provided by DS school & Origin data from Noom.
## Noom is a company that mentioned as below.
눔(Noom Inc.)은 모바일 플랫폼을 통해 건강관리 서비스를 제공하는 회사로서 2008년, 정세주 대표와 구글 수석 엔지니어 출신이자 공동창업자인 아텀 페타코브(Artem Petakov)에 의해 설립되었습니다. 눔(Noom)은 미국, 일본, 독일, 한국 등 14개국에서 4,600만명이 가입한 글로벌 서비스로 성장하였고, 2009년과 2010년 연이어 구글(Google) 이 선정한 가장 혁신적인 개발 스타트업 중 하나로 선정되었습니다.
Target
- 데이터를 불러오기 및 전반적인 정보 확인
- 불러온 데이터들을 전처리
- 데이터 분석
이번에는 마케팅팀의 요청을 살펴보도록 하겠습니다.
눔 코치와 같은 서비스에서 가장 중요시 여기는 지표는 크게 두 가지입니다.
1. 한 명의 고객을 데려오는데 필요한 비용, 줄여서 고객 획득 비용(Customer Acquision Cost, 이하 CAC)
2. 한 명의 고객을 데려왔을 때, 고객이 회사에게 제공해주는 수익(Customer Lifetime Value, 이하 LTV)
눔 코치에 헌신하는 모든 팀은 LTV를 최대한 높이고, 동시에 CAC를 최대한 낮추는 쪽으로 서비스를 개선합니다. 마케팅 팀 입장에서도 마찬가지입니다.
마케팅팀은 가능한 적은 비용을 지출하여 고객을 눔 코치에 유입시켜야 하며(CAC), 같은 CAC라면 이왕이면 회사에 많은 수익을 남겨주는 고객을 유입해야 합니다. (LTV)
이 과정에서 데이터 분석가(Data Analyst)의 역할은 매우 중요합니다.
데이터분석가는 마케팅팀에게 올바른 지표와 데이터 분석 결과를 제공해줌으로써 그들의 목적을 달성하는데 큰 도움을 줄 수 있습니다.
마케팅팀이 데이터분석가에게 요청하는 내용은 다음과 같습니다.
LTV가 높은 고객군의 인구통계학적 정보. 가령 눔 코치와 같은 다이어트 서비스에서는 남성보다 여성이 서비스의 만족도가 높고 많은 지출을 할 가능성이 있습니다.
이 경우, 페이스북 마케팅을 할 때 여성 고객들에게 집중적으로 광고를 보여주도록 타게팅 할 수 있습니다.
요일/시간별 결제 비율. 가령 주중보다 주말에 결제할 확률이 높다면, 서비스를 유료로 결제할 의사가 있는 고객들에게 주말에 결제를 유도하는 메일을 보낼 수 있습니다.
이러한 요청을 종합하며, 마케팅팀의 의사결정에 도움이 될 수 있는 정보를 뽑아보도록 하겠습니다.
결제 / 캔슬 / 환불의 총 인원 수와 비율을 구해보겠습니다.
먼저 가장 기본적인 정보는 결제 / 캔슬 / 환불 비율입니다.
전체 사용자 중에서,
1) 서비스를 유료로 이용중인 사람(completed)
2) 서비스를 더 이상 이용하지 않고 캔슬한 사람(cancelled)
3) 서비스를 결제했으나 환불한 사람(refunded)의 비율
status = clean_data["Status"].value_counts() # Status 컬럼의 값들을 status에 저장
print(status) # status 내용을 출력
dist_status = status / status.sum() # 분포를 위해 status를 status의 총합으로 나누기
dist_status*100 # 값별 비율이 어느정도인지 확인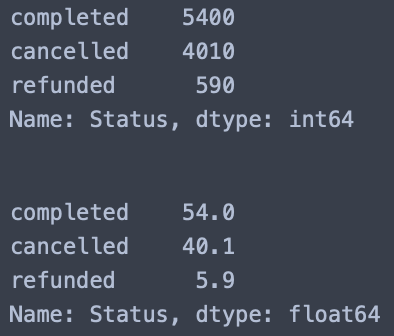
이번에는
1) 성별(남자/여자)
2) 나이에 따른 결제/캔슬/환불 비율을 알고 싶습니다. 나이의 경우 아래 기준으로 그룹을 나누고 진행하겠습니다.
2-1) 17세 이하
2-2) 18세 이상, 24세 이하
2-3) 25세 이상, 35세 이하
2-4) 36세 이상, 44세 이하
2-5) 45세 이상, 54세 이하
2-6) 55세 이상
이렇게 인구통계학적 정보로 결제/캔슬/환불 비율을 확인하면, 마케팅팀에서는 가장 결제가 많이 일어나고
캔슬/환불이 적게 일어나는 성별과 나이에 마케팅 예산을 투입할 수 있습니다.
(반대로 캔슬/환불이 빈번하게 일어나는 성별/나이에 해당하는 고객에는 마케팅 예산을 적게 집행할 것입니다)
피벗 테이블을 활용해 성별 그리고 Status 기준으로 간단히 데이터를 확인하고 컬럼들을 세분화 해보겠습니다.
clean_data.pivot_table(index = 'Gender(clean)', columns = 'Status',\
values='Age(clean)' ,aggfunc='count')
이제 컬럼들을 나이대에 맞춰 세분화 해보겠습니다.
# 나이(Age(clean))가 17세 이하인 사용자를 찾아서 Age(Group) 컬럼에 "00 ~ 17"이라는 값을 넣어줍니다
clean_data.loc[clean_data['Age(clean)'] <= 17, 'Age(Group)'] = "00 ~ 17"
# 위 방식에 따라 나이 설정 값으로 지정해줍니다
clean_data.loc[(clean_data['Age(clean)'] >= 18) &\
(clean_data['Age(clean)'] <= 24), 'Age(Group)'] = "18 ~ 24"
clean_data.loc[(clean_data['Age(clean)'] >= 25) &\
(clean_data['Age(clean)'] <= 35), 'Age(Group)'] = "25 ~ 35"
clean_data.loc[(clean_data['Age(clean)'] >= 36) &\
(clean_data['Age(clean)'] <= 44), 'Age(Group)'] = "36 ~ 44"
clean_data.loc[(clean_data['Age(clean)'] >= 45) &\
(clean_data['Age(clean)'] <= 54), 'Age(Group)'] = "45 ~ 54"
clean_data.loc[clean_data['Age(clean)'] >= 55, 'Age(Group)'] = "55 ~ 99"
# 데이터를 정리 후 아래 2개 컬럼 내용을 확인합니다
clean_data[['Age(clean)','Age(Group)']]
위 Age(Group) 컬럼을 활용하여 성별과 나이대에 따른 캔슬/완료/환불 결과를 확인해보겠습니다.
# pivot_table을 사용하여 index(세로)에는 성별(Gender(clean))과 나이(Age(Group))를 넣어주고,
# Columns(가로)에는 Status를 넣어줍니다
# 여기서 fill_value에 0을 넣어줘야, 데이터가 없을 경우 NaN이 아닌 0이 나옵니다
# 그리고 aggfunc에 len 혹은 count를 넣어주면 cancelled, completed, refunded의 누적 개수가 나옵니다
table = pd.pivot_table(clean_data,
index=["Gender(clean)", "Age(Group)"],
columns="Status",
values="Gender",
fill_value=0,
aggfunc='count')
# 이 데이터프레임의 결과를 출력합니다
table
결과가 잘 확인 되었습니다. 이번에는 추가적으로 Age(Group)에 따른 분포 상태와 전환율을 확인해보겠습니다.
# completed, cancelled, refunded의 총 인원 수를 더해서 total이라는 새로운 컬럼을 추가합니다
table["total"] = table["completed"] + table["cancelled"] + table["refunded"]
# 위에서 추가한 total이라는 컬럼으로 completed(결제 완료) 컬럼을 나누면 결제 확률, 전환율(Conversion)이 나옵니다
table["conversion"] = table["completed"] / table["total"]
# 이 데이터프레임의 결과를 출력합니다
table
결과가 잘 확인되었습니다.
분석 결과는 다음과 같습니다.
- 가장 많은 양의 결제가 일어난 구간은 여성 25 ~ 35세입니다. 총 2288개로, 결제 완료의 40% 이상이 이 구간에서 발생했습니다. 심지어 전환율(conversion)도 54.1%로 평균 이상입니다.
- 또한 어느 정도 모수가 받쳐주는(결제 완료 100회 이상) 채널 중 이보다 전환율이 높은 채널은 1) 여성 36 ~ 54세, 2) 남성 25 ~ 35세, 3) 남성 36 ~ 44세 입니다. 이 채널들은 전환율이 60% 이상으로 매우 높습니다.
- 다만 이 채널들의 총 결제자(total)가 낮다는 것은 1) 아직 이 마케팅 채널이 최적화가 덜 되었거나, 2) 고객 획득 비용(CAC)이 높은 편이라 마케팅 비용을 늘리지 않았을 가능성이 있습니다. 또한 아주 희소한 경우이지만, 3) 주 마케팅 채널(ex: 페이스북)에 위 채널에 해당하는 고객의 인원수가 부족할 수도 있습니다.
이런 상황에서, 데이터분석가는 퍼포먼스 마케터와 함께 다음의 아이디어를 제시하여 회사의 매출을 증대할 수 있습니다.
- 마케팅 예산을 여성 36 ~ 54세쪽에 집중한다. 이 채널이 전환율이 높기 때문에, CAC가 여성 25 ~ 35세와 동일하다면 여성 36 ~ 54세에 마케팅 예산을 늘리는 것은 좋은 전략입니다.
- 여성 36 ~ 54세 채널의 CAC가 상대적으로 높다면, 이 CAC을 낮추는 시도를 합니다. 이 전략이 성공하면 그 후에 마케팅 예산을 집중하는 것도 방법입니다.
- 현재 이용하고 있는 광고 채널을 다각화하여, 여성 36 ~ 54세가 활동하는 곳에 집중적으로 마케팅 예산을 투입하는 것도 시도해볼만 합니다.
다음 페이지에서는 본 환경을 이어서 분석을 진행하도록 하겠습니다.
*** 본 페이지는 본인의 공부를 위해 작성되었으며, 협찬이나 문의를 받고 기재한 내용이 아닙니다. 혹시 문의사항이 있으시거나 문제가 될 경우 연락 주시기 바랍니다.***
'데이터 분석 > Python - 정리하자' 카테고리의 다른 글
| 마케팅 채널별 결제/캔슬/환불 비율 구하기 (0) | 2024.07.08 |
|---|---|
| 전환율(conversion) 구해보기 (+시각화) (0) | 2024.07.08 |
| VIP 찾기 데이터 분석 (0) | 2024.07.07 |
| 건강관리 현업 데이터로 전처리 (0) | 2024.07.06 |
| 건강관리 현업 데이터로 인덱싱 (0) | 2024.07.06 |



