# 구동 환경 : Postgre SQL 12.3 설치 -> pgAdmin4에서 아래 DB 연동 -> DBeaver 7.1.1 버전에서 코딩 진행
# 활용하는 DB = dvdrental.tar
PostgreSQL의 SELECT DISTINCT 문: 사용 이유와 중요성
SELECT DISTINCT 문은 데이터베이스에서 중복된 행을 제거하여 고유한 결과를 반환하는 SQL 명령어입니다. 이 문장은 데이터베이스 관리 및 분석에서 중요한 역할을 합니다. 왜 SELECT DISTINCT 문을 사용해야 하며, 무엇이 중요한지에 대해 살펴보겠습니다.
SELECT DISTINCT 문을 왜 사용할까?
- 데이터 중복 제거: 데이터베이스에는 종종 중복된 데이터가 포함될 수 있습니다. SELECT DISTINCT 문은 이러한 중복된 데이터를 제거하고 고유한 값만을 조회할 수 있게 합니다. 이는 데이터의 정확성과 일관성을 유지하는 데 중요합니다.
- 정확한 데이터 분석: 분석을 수행할 때 중복된 데이터는 분석 결과를 왜곡할 수 있습니다. SELECT DISTINCT 문을 사용하면 정확한 분석을 위한 고유한 데이터 집합을 얻을 수 있습니다.
- 효율적인 보고서 생성: 보고서 작성 시 중복된 데이터는 혼란을 야기할 수 있습니다. 고유한 값을 조회함으로써 보다 명확하고 신뢰할 수 있는 보고서를 생성할 수 있습니다.
- 데이터 무결성 유지: 중복된 데이터는 데이터 무결성을 해칠 수 있습니다. SELECT DISTINCT 문을 통해 중복을 제거함으로써 데이터 무결성을 유지할 수 있습니다.
SELECT DISTINCT 문의 중요성은?
- 데이터 정확성 향상: 데이터베이스에서 중복된 데이터를 제거하여 고유한 값만을 반환함으로써 데이터의 정확성을 향상시킬 수 있습니다. 이는 데이터 분석과 보고서 작성에서 매우 중요합니다.
- 데이터 무결성 보장: 중복된 데이터는 데이터 무결성을 저해할 수 있습니다. SELECT DISTINCT 문을 사용하여 중복을 제거하면 데이터 무결성을 보장할 수 있습니다.
- 쿼리 성능 최적화: 중복된 데이터를 조회하지 않음으로써 쿼리 성능을 최적화할 수 있습니다. 이는 대규모 데이터베이스에서 특히 유용합니다.
- 효과적인 데이터 관리: 고유한 값을 조회함으로써 데이터베이스를 보다 효과적으로 관리할 수 있습니다. 이는 데이터베이스 유지 보수와 관리에 있어서 중요한 요소입니다.
Select Distinct 문은 중복 값을 제외한 결과값을 보고 싶을때 사용하실 수 있습니다.
Select distinct문은 새로운 샘플용 테이블을 생성 후 진행해 보겠습니다.
CREATE TABLE T1 (ID SERIAL NOT NULL PRIMARY KEY, BCOLOR VARCHAR, fcolor varchar);
-- T1 테이블 생성테이블 부터 생성해줍니다.
생성이 완료되었고 다음으로 값들을 생성 후 적용(commit)해 보겠습니다.
-------------- 1차 진행
INSERT
INTO T1 (BCOLOR, FCOLOR)
VALUES
('RED', 'RED')
,('RED', 'RED')
,('RED', NULL)
,( NULL, 'RED')
,('RED', 'GREEN')
,('RED', 'BLUE')
,('GREEN','RED')
,('GREEN', 'BLUE')
,('GREEN', 'GREEN')
,('BLUE', 'RED')
,('BLUE', 'GREEN')
,('BLUE', 'BLUE')
;
-------------- 2차 진행
commit;
--------------1차 진행만큼 드래그 후 실행해서 데이터들을 먼저 입력해주시고 2차로 commit을 사용해서 테이블에 데이터를 적용해줍니다.
적용 후 데이터를 확인해보겠습니다.
SELECT
*
FROM
T1;
생성된 테이블로 하나씩 select distinct문을 활용해보겠습니다.
SELECT
DISTINCT BCOLOR -- BCOLOR 컬럼에서 중복 내용 확인
FROM
T1 -- T1 테이블 선택
ORDER BY
BCOLOR -- 해당 컬럼에서 정렬(default값은 오름차순 입니다)
;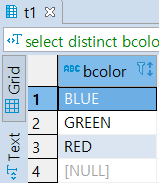
총 12개 값 중 중복값을 제외하고 4개의 데이터가 걸러졌습니다.
이번에는 전체 항목에서 중복 데이터를 걸러보겠습니다.
SELECT
DISTINCT BCOLOR, FCOLOR -- 값들 중 두개 컬럼 모두 중복인 데이터 거르기
FROM
T1 -- T1 테이블 선택
ORDER BY
BCOLOR, FCOLOR -- 두개 컬럼으로 정렬(default는 오름차순 입니다.)
;
보시면 왼쪽편은 모든 데이터를 불러왔고 오른쪽은 select distinct를 통해 중복 내용을 제거한 테이블입니다.
BCOLOR와 FCOLOR 두 컬럼 모두 중복되는 데이터는 하나이므로 그 부분이 걸러진것은 확인할 수 있습니다.
이번에는 select distinct on 을 활용해서 한 컬럼 내에서 중복되는 데이터를 삭제하는 방식으로 해보겠습니다.
SELECT
DISTINCT on (BCOLOR) -- BCOLOR 컬럼 선택
BCOLOR -- BCOLOR 에서 중복 데이터 확인
, FCOLOR
FROM
T1 -- T1 테이블 선택
ORDER BY
BCOLOR, FCOLOR
-- BCOLOR와 FCOLOR로 정렬하는데 FCOLOR 정렬시 a b c 순으로 정렬되므로 FCOLOR 값은 BLUE로 출력됨
;
값이 설명 드린부분에 맞게 걸러졌습니다.
이번에는 내림차순 정렬을 했을때 값을 확인해보겠습니다.
SELECT
DISTINCT on (BCOLOR) -- BCOLOR 컬럼 선택
BCOLOR -- BCOLOR 에서 중복 데이터 확인
, FCOLOR
FROM
T1 -- T1 테이블 선택
ORDER BY
BCOLOR, FCOLOR DESC
-- BCOLOR와 FCOLOR로 정렬하는데 FCOLOR 정렬시 내림차순 정렬되므로 FCOLOR 값은 RED로 출력됨
;
값이 설명 드린부분에 맞게 걸러졌습니다.
결론
PostgreSQL의 SELECT DISTINCT 문은 데이터베이스에서 중복된 데이터를 제거하고 고유한 값을 조회하는 데 필수적인 도구입니다. 이를 통해 데이터의 정확성을 향상시키고, 데이터 무결성을 유지하며, 쿼리 성능을 최적화할 수 있습니다. 또한, 고유한 값을 조회함으로써 데이터베이스를 효과적으로 관리하고 분석할 수 있습니다.
다음에는 WHERE 문에 대해서 보도록 하겠습니다.
'데이터 분석 > Postgre SQL - 정리하자' 카테고리의 다른 글
| Limit 문은 언제 어떻게 쓰일까? (0) | 2024.07.10 |
|---|---|
| Where 문 활용하기 (0) | 2024.07.10 |
| Order By 문 활용법 (2) | 2024.07.05 |
| Select 문을 어떻게 쓸 수 있을까? (0) | 2024.07.05 |
| Postgre SQL 나홀로 스터디 시작 (0) | 2024.07.05 |



